


0.1、索引
https://waterflow.link/articles/1666090530880
1、概念
1.1、源文件里的代码执行顺序
init 函数是用于初始化应用程序状态的函数。 它不接受任何参数并且不返回任何结果(一个 func() 函数)。 初始化包时,将初始化包中的所有常量和变量声明。 然后,执行初始化函数。 下面是一个初始化主包的例子:
package main
import "fmt"
// 1
var a = func() int {
fmt.Println("var a")
return 0
}()
// 2
func init() {
fmt.Println("init")
}
// 1
var b = func() int {
fmt.Println("var b")
return 1
}()
// 3
func main() {
fmt.Println("main")
}
上面代码的初始化顺序是:
- 初始化常量/变量(虽然 b 在 init 函数后面,但是会首先初始化)
- 初始化 init 函数
- 执行 main 函数
我们看下打印的结果:
go run 2.go
var a
var b
init
main
1.2、不同包的 init 函数执行顺序
初始化包时会执行一个 init 函数。 在下面的例子中,我们定义了两个包,main 和 Redis,其中 main 依赖于 Redis。 首先, 2 .go 是主包:
package main
import (
"fmt"
"go-demo/100gomistakes/2/redis"
)
// 2
func init() {
fmt.Println("main init")
}
// 3
func main() {
err := redis.Store("ni", "hao")
fmt.Println(err)
}
我们可以看到 main 包中调用了 Redis 包的方法。
我们再看下 Redis 包中的内容:
package redis
import "fmt"
// 1
func init() {
fmt.Println("redis init")
}
func Store(key, value string) error {
return nil
}
因为 main 依赖 Redis,所以先执行 Redis 包的 init 函数,然后是 main 包的 init,然后是 main 函数本身。上面的代码中标明了执行顺序。
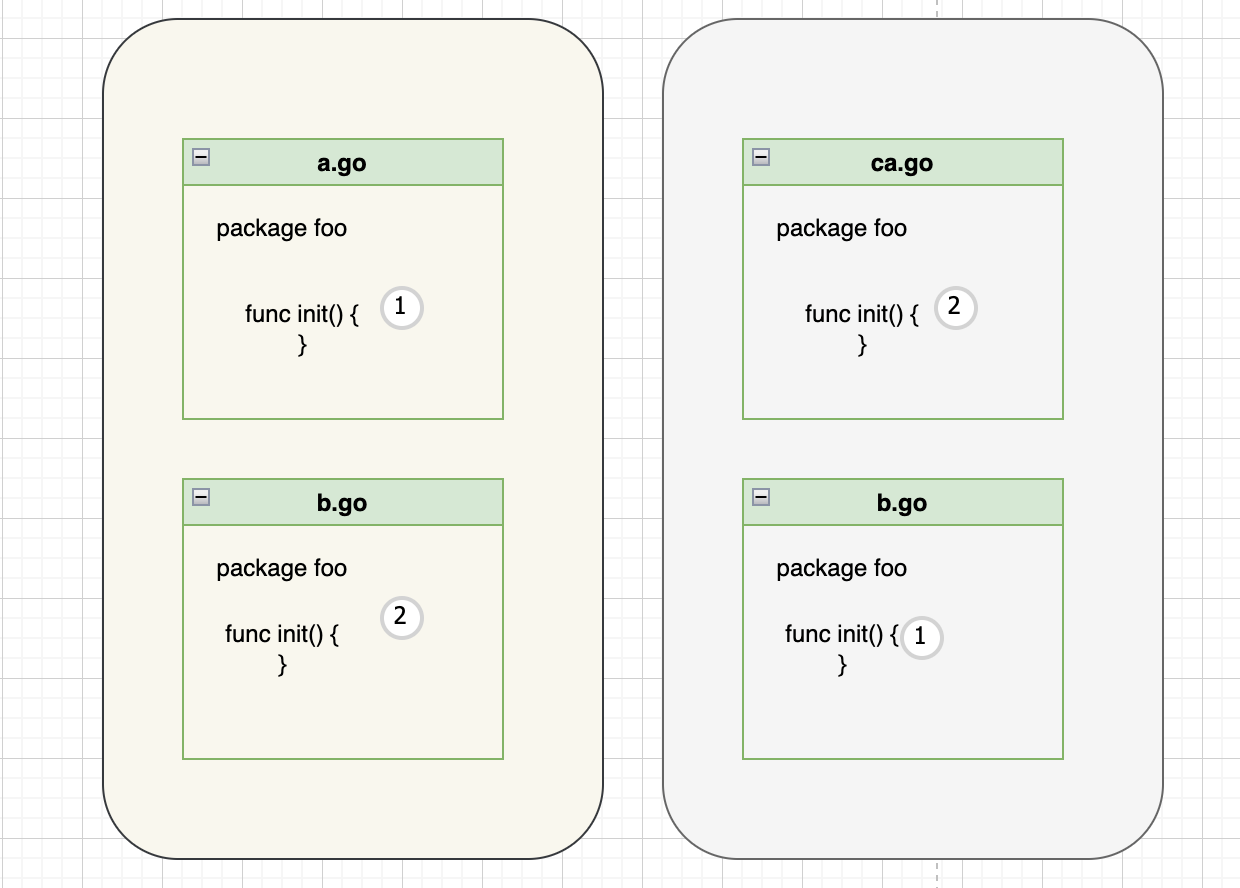
1.3、同一个包不同文件 init 执行顺序
我们可以为每个包定义多个初始化函数。 当我们这样做时,包内的 init 函数的执行顺序是基于源文件的字母顺序。 例如,如果一个包包含一个 a.go 文件和一个 b.go 文件,并且都有一个 init 函数,则首先执行 a.go init 函数。
但是如果我们把文件 a.go 改为 ca.go,则会先执行 b.go 的 init 函数。
所以我们不应该依赖包中初始化函数的顺序。 实际上,这可能很危险,因为可以重命名源文件,从而可能影响执行顺序。
下图说明了这个问题:
1.4、同一个文件中的 init 函数
当然,我们还可以在同一个源文件中定义多个初始化函数:
package main
import (
"fmt"
"go-demo/100gomistakes/2/redis"
)
func init() {
fmt.Println("main init1")
}
func init() {
fmt.Println("main init2")
}
func main() {
err := redis.Store("ni", "hao")
fmt.Println(err)
}
执行顺序是按照源文件顺序执行的,我们看下打印的结果:
go run 2.go
redis2 init
redis init
main init1
main init2
<nil>
1.5、以副作用方式执行的 init 函数
我们开发的时候经常会使用 GORM 查询数据库,所以我们经常会看到在初始化 db 连接的时候会有下面的代码:
package models
import (
_ "github.com/go-sql-driver/mysql"
"github.com/jinzhu/gorm"
)
这种情况就是说,我们没有强依赖 MySQL 包(没有直接使用 MySQL 的公共函数)。但是我们需要初始化 MySQL 包里的一些数据,也就是执行 MySQL 包里的 init 函数。这个时候我们就可以在这个包的前面加上 _。
需要注意的是 init 函数不能被当作普通函数调用,会编译报错。
2、使用场景
首先,让我们看一个使用 init 函数可能被认为不合适的示例:持有数据库连接池。 在示例的 init 函数中,我们使用 sql.Open 打开一个数据库。 这个全局变量 db 会被其他函数调用:
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"log"
)
var db *sql.DB
func init() {
d, err := sql.Open("mysql",
"root:liufutian@tcp(127.0.0.1:3306)/test")
if err != nil {
log.Panic(err)
}
err := db.Ping()
if err != nil {
log.Panic(err)
}
db = d
}
func main() {
}
在本例中,我们打开数据库,检查是否可以 ping 通,然后将其分配给全局变量。
但是这种实现会带来一些问题:
- init 函数中的错误管理是有限的。 实际上,由于 init 函数不返回错误,因此发出错误信号的唯一方法之一就是 panic,导致应用程序停止。 在我们的示例中,如果打开数据库失败,无论如何都会停止应用程序。 但是,不一定要由包本身来决定是否停止应用程序。 有可能调用者想实现重试或使用回退机制。 在这种情况下,在 init 函数中打开数据库会阻止客户端包实现其错误处理逻辑。
- 如果我们向这个文件添加测试,init 函数将在运行测试用例之前执行,但是我们想要的是创建 db 连接的时候需要测试。 因此,此示例中的 init 函数使编写单元测试变得复杂。
- 该示例需要将数据库连接池分配给全局变量。 全局变量有一些严重的缺点; 例如:
- 任何函数都可以更改包中的全局变量
- 单元测试可能会更复杂,因为依赖于全局变量的函数将不再被隔离
在大多数情况下,我们应该倾向于封装一个变量而不是让它保持全局。
由于这些原因,之前的初始化可能应该封装到一个函数中处理,如下所示:
func createDB() (*sql.DB, error) {
d, err := sql.Open("mysql",
"root:liufutian@tcp(127.0.0.1:3306)/test")
if err != nil {
return nil, err
}
err = db.Ping()
if err != nil {
return nil, err
}
return d, nil
}
这样写的话,我们解决了之前讨论的主要缺点:
- 是否处理错误留给调用者
- 可以创建一个集成测试来检查此功能是否有效
- 连接池封装在函数中
但是这样就是不能使用 init 函数了么?在我们上面的引入 MySQL 驱动的例子中,说明使用 init 还是有帮助的:
func init() {
sql.Register("mysql", &MySQLDriver{})
}
上面的例子,通过注册提供的驱动名称使数据库驱动程序可用。